一次真实的 Docker + PHP-FPM 内存溢出排障全过程——从“慢查询查不到”到“OOM Killer 现场还原”
2026-01-28
这是一次典型但又极容易被误判的线上事故:
接口偶发卡死、失败,慢查询查不到,MySQL 看起来也“没报错”,
但系统却在某个时间点反复异常。
下面完整记录一次从零线索开始,到最终定性并给出可执行解决方案的全过程。
一、问题起点:昨天 11 点左右系统异常,但慢查询是关的
事故发生时间非常明确:
昨天上午 11 点左右,系统出现异常。
第一反应是查 MySQL 慢查询,但很快确认:
slow_query_log = OFF事后无法回溯历史慢 SQL
结论 1(必须先接受的现实):
MySQL 没有提前开启慢查询,SQL 层已经“不可追溯”。
这一步不是失败,而是排除了一个方向,逼着我们往更底层走。
二、转换排查方向:是否发生了内存溢出(OOM)
在 Docker + PHP-FPM 架构下,内存问题是少数“事后还能查到尸检报告”的问题,因为:
Linux 内核会记录 OOM
Docker / cgroup 会记录内存约束
PHP-FPM 会留下异常退出痕迹
使用的关键命令:
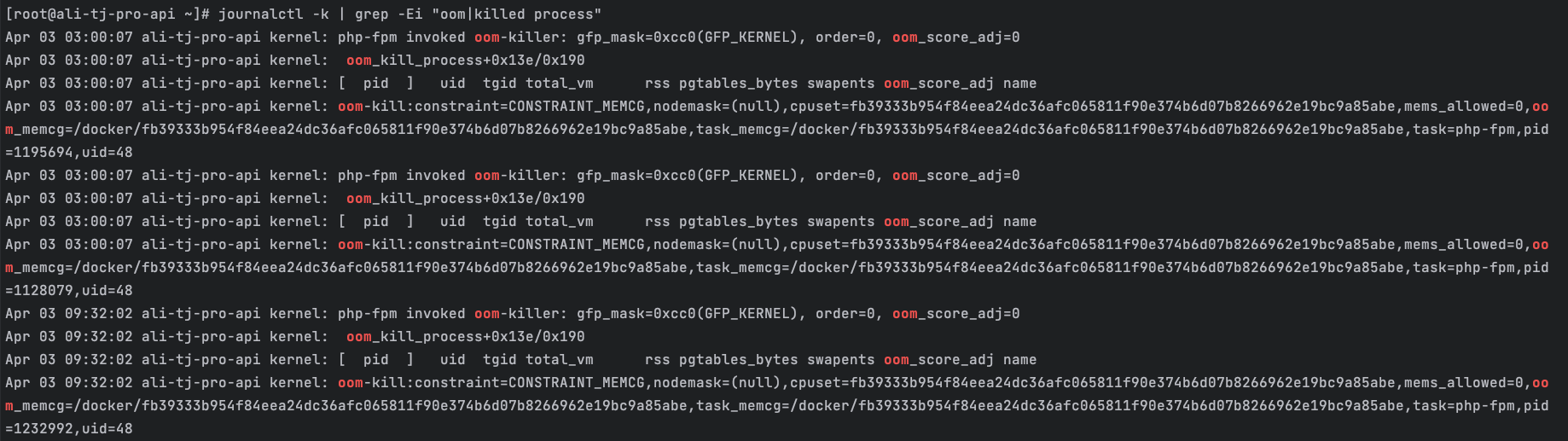
journalctl -k | grep -Ei "oom|killed process"
三、第一份铁证:内核 OOM 日志(决定性证据)
从内核日志中,出现了反复的关键信息:
php-fpm invoked oom-killerconstraint=CONSTRAINT_MEMCGoom_memcg=/docker/xxxxxtask=php-fpm
这里信息量极大:
不是 MySQL OOM
不是整台宿主机 OOM
是 Docker cgroup 内存限制触发
被杀进程是 php-fpm worker
而且时间点正好覆盖昨天 11 点左右,并且并非第一次发生(历史上多次)。
结论 2:
这是一个长期存在的 PHP-FPM 内存问题,不是偶发事故。
四、第二份铁证:PHP-FPM 自身的 SIGKILL 日志
继续查看 PHP-FPM 的 error log,发现如下内容:
[27-Jan-2026 11:48:57] WARNING: [pool www] child 13605 exited on signal 9 (SIGKILL) [27-Jan-2026 11:48:57] NOTICE: [pool www] child 13707 started
这两行日志非常关键。
含义拆解:
SIGKILL (9):
不是 PHP 自己退出,而是被系统强制杀死child exited后立刻child started:
FPM master 在自救,重启 worker
结合内核 OOM 日志,可以确定:
结论 3:
PHP-FPM worker 在执行过程中被 OOM Killer 直接处决。
五、第三步:确认 Docker 容器的内存配置
接下来要确认:
是不是容器内存本身太小?
执行:
docker inspect <container> | grep -i memory
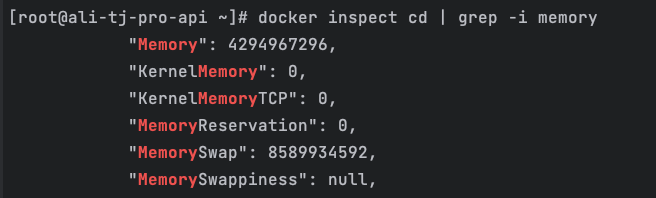
结果显示:
Memory = 4GBMemorySwap = 8GB
这一步非常重要,因为它直接排除了一个常见误解。
结论 4:
4GB 内存 + 4GB swap,本身并不算“小容器”。
也就是说:
问题不是“内存配得太抠”,而是某些请求在疯狂吃内存。
六、进一步定位:为什么 PHP 会吃掉这么多内存?
此时我们已经可以确定:
OOM 发生在 PHP-FPM
是容器 MEMCG 限制触发
不是 SQL 慢、不是 MySQL 爆
接下来必须结合业务。
一个关键事实被确认:
存在一个“单次 11MB 数据写入数据库”的操作,并且可能同时跑 5 个。
表数据规模:几千万级。
这正是整个事故的根因入口。
七、关键认知转变:11MB ≠ 内存里的 11MB
这是很多人(包括有经验的工程师)最容易误判的地方。
在真实 PHP 运行时,11MB 会经历什么?
JSON / 请求体解析
11MB JSON → PHP 数组
内存膨胀 3~10 倍(zval 结构)
数组加工 / 映射 / 合并
array_maparray_merge数据校验、字段补全
👉 产生多份副本SQL 构造
批量 INSERT 拼成长字符串
👉 又是一份大内存ORM / ActiveRecord
一行数据 = 一个对象
几千行就是几千个对象
一个保守的真实模型:
11MB 输入
内存峰值 300MB~1GB / 单请求
5 个并发:
300MB × 5 = 1.5GB(轻度)
1GB × 5 = 5GB(直接穿)
再加上:
PHP-FPM worker 不会及时释放内存
其他 worker + opcache + 系统开销
4GB 内存 + swap 被顶穿,完全合理。
八、为什么 swap 没救回来?
这是另一个常见疑问。
关键点在于:
这是 cgroup MEMCG OOM,不是传统意义上的“全局内存耗尽”。
内核在容器级别判断内存不可满足
高阶页分配失败
swap 使用受策略限制
OOM Killer 会提前介入
结论 5:
在 Docker 场景下,不能指望 swap 兜底。
九、为什么“ps 查 RSS”也查不到昨天的数据?
你曾尝试:
ps -o pid,rss,cmd -C php-fpm
但想加上时间范围(11:40–12:00)。
这里需要明确一个事实:
结论 6:
Linux 不保存历史进程 RSS。
/proc是实时视图,不是日志。
进程被 kill 后:
/proc/<pid>消失RSS 信息不可恢复
所以这是工具能力边界问题,不是命令写错。
十、最终结论(完整定性)
综合所有证据:
内核 OOM 日志(MEMCG)
PHP-FPM SIGKILL
Docker 内存配置
业务写入模型
并发事实
最终定性:
多个并发的大数据写入请求,导致 PHP-FPM worker 内存持续膨胀,
在 Docker 容器内触发 cgroup OOM,被内核强制 kill。
十一、可落地的解决方案(不是“建议”,而是顺序)
1️⃣ 立刻止血(不改业务逻辑也要做)
PHP-FPM pool 配置:
pm.max_requests = 300 php_admin_value[memory_limit] = 512M
作用:
防止 worker “慢性变胖”
让超限请求在 PHP 层失败,而不是拖死整个容器
2️⃣ 并发控制(极其关键)
对于该写入接口:
同一时间并发 ≤ 1~2
可用:
Redis 锁
队列
Nginx 限流
3️⃣ 写入方式改造(核心)
不要一次性吃 11MB
分批(500~2000 行)写入
每批写完释放内存
避免
all()、大数组长期驻留
4️⃣ 架构级优化(中长期)
写入从 HTTP → 队列 → CLI worker
CLI worker 单独提高 memory_limit
表分区 / 分表
减少写入时的索引负担
十二、这次排障真正的价值
这次问题的价值,不在于“解决了一个 OOM”,而在于:
学会了 证据链式排障
明白了 Docker + PHP 的真实内存模型
知道了 什么问题是事后查不到的
以及:
为什么很多系统“看起来没问题”,但会突然炸
图片插入顺序总结(你写文章时用)
图片 1
journalctl -k | grep -Ei "oom|killed process"的结果
👉 放在「内核 OOM 定性」那一节图片 2
docker inspect <container> | grep -i memory的结果
👉 放在「Docker 内存配置确认」那一节
发表评论: